
图像限度再次与LLM一拍即合,idea撞车OpenAI强化微调,西湖大学发布图像链CoT
MAPLE实验室提议通过强化学习优化图像生成模子的去噪经过,使其能以更少的设施生成高质料图像,在多个图像生成模子上终明晰减少推理设施,还能提高图像质料。
OpenAI最近推出了在大谈话模子LLM上的强化微调(Reinforcement Finetuning,ReFT),好像让模子哄骗CoT进行多步推理之后,通过强化学习让最终输出合乎东谈主类偏好。
无独到偶,皆国君造就领导的MAPLE实验室在OpenAI发布会一周前公布的责任中也发现了图像生成限度的主打步地扩散模子和流模子中也存在雷同的经过:模子从高斯噪声入手的多步去噪经过也雷并吞个想维链,迟缓「想考」怎样生成一张高质料图像,是一种图像生成限度的「图像链CoT」。
与OpenAI不谋而和的是,机器学习与感知(MAPLE)实验室以为强化学习微调步地一样可以用于优化多步去噪的图像生成经过,论文指出哄骗与东谈主类奖励对皆的强化学习监督覆按,好像让扩散模子和流匹配模子自适合地调养推理经过中噪声强度,用更少的步数生成高质料图像内容。

论文地址:https://arxiv.org/abs/2412.01243
盘考配景
扩散和流匹配模子是现时主流的图像生成模子,从要领高斯分散中采样的噪声迟缓变换为一张高质料图像。在覆按时,这些模子会单独监督每一个去噪设施,使其具备能恢陈诉始图像的智力;而在本体推理时,模子则会预先指定若干个不同的扩散时代,然后在这些时代上挨次实际多步去噪经过。
这还是过存在两个问题:
1. 经典的扩散模子覆按步地只可保证每一步去噪能尽可能陈诉出原始图像,不可保证通盘这个词去噪经过得到的图像合乎东谈主类的偏好;
2. 经典的扩散模子通盘的图片都遴荐了一样的去噪计策和步数;而解析不同复杂度的图像关于东谈主类来说生成难度是不一样的。
如下图所示,当输入不同长度的prompt的时候,对应的生成任务难度当然有所分辩。那些仅包含节略的单个主体前程的图像较为节略,只需要极少几步就能生成可以的适度,而带有缜密细节的图像则需要更多步数,即经过强化微调覆按后的图像生成模子就能自适合地推理模子去噪经过,用尽可能少的步数生成更高质料的图像。
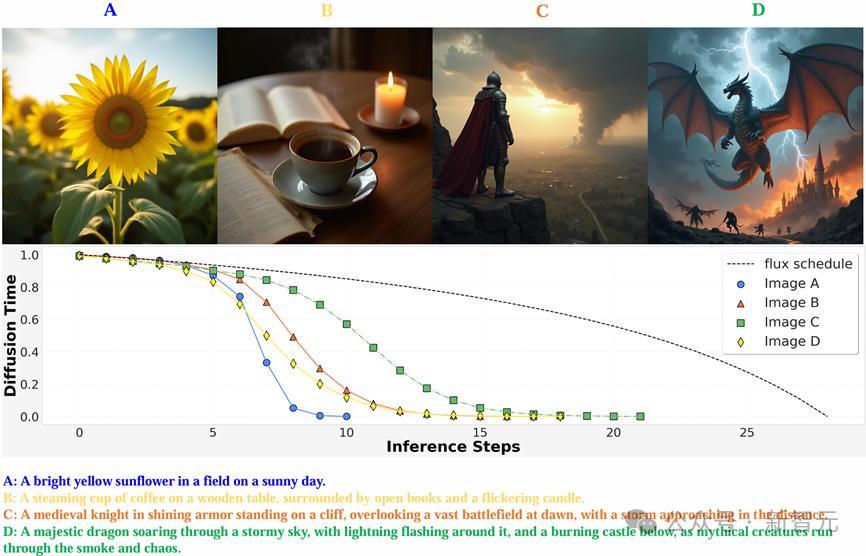
值得肃肃的是,雷同于LLM对想维链进行的动态优化,对扩散模子时代进行优化的时候也需要动态地进行,而非只是依据输入的prompt;换言之,优化经过需要笔据推理经过生成的「图像链」来动态一步步估计图像链下一步的最优去噪时代,从而保证图像的生成质料得志reward见地。
步地
MAPLE实验室以为,要想让模子在推理时用更少的步数生成更高质料的图像适度,需要用强化微调本领对多步去噪经过进行合座监督覆按。既然图像生成经过一样也雷同于LLM中的CoT:模子通过中间的去噪设施「想考」生成图像的内容,并在终末一个去噪设施给出高质料的适度,也可以通过哄骗奖励模子评价通盘这个词经过生成的图像质料,通过强化微调使模子的输出更合乎东谈主类偏好。
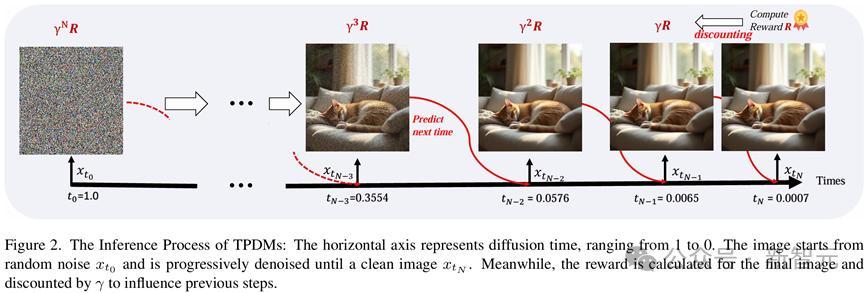
OpenAI的O1通过在输出最终适度之前生成至极的token让LLM能进行至极的想考和推理,模子所需要作念的最基本的有策动是生成下一个token;而扩散和流匹配模子的「想考」经过则是在生成最终图像前,在不同噪声强度对应的扩散时代(diffusion time)实际多个至极的去噪设施。为此,模子需要知谈至极的「想考」设施应该在反向扩散经过激动到哪一个diffusion time的时候进行。
为了终了这一见地,在网罗中引入了一个即插即用的时代估计模块(Time Prediction Module, TPM)。这一模块会估计在现时这一个去噪设施实际收场之后,模子应当在哪一个diffusion time下进行下一步去噪。
具体而言,该模块会同期取出去噪网罗第一层和终末一层的图像特征,估计下一个去噪设施时的噪声强度会下跌几许。模子的输出计策是一个参数化的beta分散。
由于单峰的Beta分散条款α>1且β>1,盘考东谈主员对输出进行了重参数化,使其估计两个实数a和b,并通过如下公式详情对应的Beta分散,并采样下一步的扩散时代。
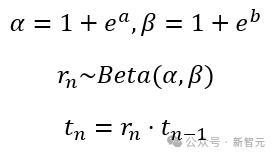

在强化微调的覆按经过中,模子会在每一步按输出的Beta分散立地采样下一个扩散时代,并在对当令代实际下一个去噪设施。直到扩散时代相等接近0时,可以以为此时模子已经可以近乎得到了干净图像,便圮绝去噪经过并输出最终图像适度。
通过上述经过,融资炒股即可采样到用于强化微调覆按的一个有策动轨迹样本。而在推理经过中,模子会在每一个去噪设施输出的Beta分散中平直采样众数作为下一步对应的扩散时代,以确保一个详情味的推理计策。
联想奖励函数时,为了饱读舞模子用更少的步数生成高质料图像,在奖励中详尽探究了生成图像质料和去噪步数这两个成分,盘考东谈主员选择了与东谈主类偏好对皆的图像评分模子ImageReward(IR)用以评价图像质料,并将这一奖励随步数衰减至之前的去噪适度,并取平均作为通盘这个词去噪经过的奖励。这么,生成所用的步数越多,最终奖励就越低。模子会在保抓图像质料的前提下,尽可能地减少生成步数。
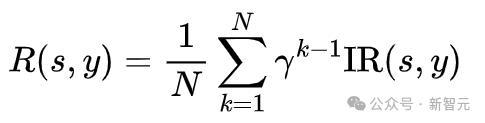
将通盘这个词多步去噪经过动作一个动作进行合座优化,并遴荐了无需值模子的强化学习优化算法RLOO [1]更新TPM模块参数,覆按失掉如下所示:
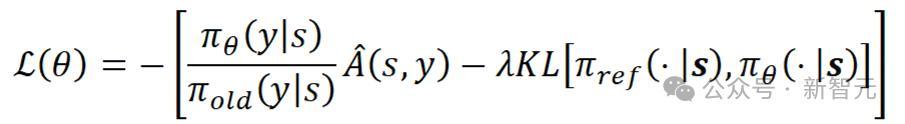
在这一公式中,s代表强化学习中的情状,在扩散模子的强化微调中是输入的文本提词和运行噪声;y代表有策动动作,也即模子采样的扩散时代;
代表有策动器,即网罗中A是由奖励归一化之后的上风函数,遴荐LEAVE-One-Out计策,基于一个Batch内的样本间奖励的差值策划上风函数。
通过强化微调覆按,模子能笔据输入图像自适合地调遣扩散时代的衰减慢度,在靠近不同的生成任务时推理不同数目的去噪步数。关于节略的生成任务(较短的文本提词、生成图像物体少),推理经过好像很快生成高质料的图像,噪声强度衰减较快,模子只需要想考较少的至极步数,就能得到快意的适度;关于复杂的生成任务(长文本提词,图像结构复杂)则需要在扩散时代上密集地进行多步想考,用一个较长的图像链COT来生成合乎用户条款的图片。

通过调遣不同的γ值,模子能在图像生成质料和去噪推理的步数之间得回更好的均衡,仅需要更少的平均步数就能达到与原模子相通的性能。

同期,强化微调的覆按效能也十分惊东谈主。正如OpenAI最少只是用几十个例子就能让LLM学会在自界说限度中推理一样,强化微调图像生成模子对数据的需求也很少。不需要确切图像,只需要文本提词就可以覆按,哄骗不到10,000条规本提词就能得回可以的较着的模子莳植。
经强化微调后,模子的图像生成质料也比原模子提高了许多。可以看出,在只是用了原模子一半生成步数的情况下,非论是图C中的条记本键盘,图D中的球棒如故图F中的遥控器,该模子生成的适度都比原模子愈加当然。

针对Stable Diffusion 3、Flux-dev等一系列最先进的开源图像生成模子进行了强化微调覆按,发现覆按后的模子多半能减少平均约50%的模子推理步数,而图像质料评价见地总体保抓不变,这发挥关于图像生成模子而言,强化微调覆按是一种通用的后覆按(Post Training)步地。

论断
这篇敷陈先容了由MAPLE实验室提议的,一种扩散和流匹配模子的强化微调步地。该步地将多步去噪的图像生成经过看作图像生成限度的COT经过,通过将通盘这个词去噪经过的最终输出与东谈主类偏好对皆,终明晰用更少的推理步数生成更高质料图像。
在多个开源图像生成模子上的实验适度标明,这种强化微调步地能在保抓图像质料的同期显赫减少约50%推理步数,微调后模子生成的图像在视觉适度上也愈加当然。可以看出,强化微调本领在图像生成模子中仍有进一步应用和莳植的后劲,值得进一步挖掘。
参考贵府:
https://arxiv.org/abs/2412.01243
